How to calculate availability of the system?
In the world of system reliability and maintenance, availability is a critical metric that signifies how often a system is operational and accessible when required. Two key metrics that contribute to calculating availability are Mean Time Between Failures (MTBF) and Mean Time to Repair (MTTR). Let’s delve into these concepts, understand their significance, and see how they are used in availability calculation with comprehensive examples.
What is Availability?
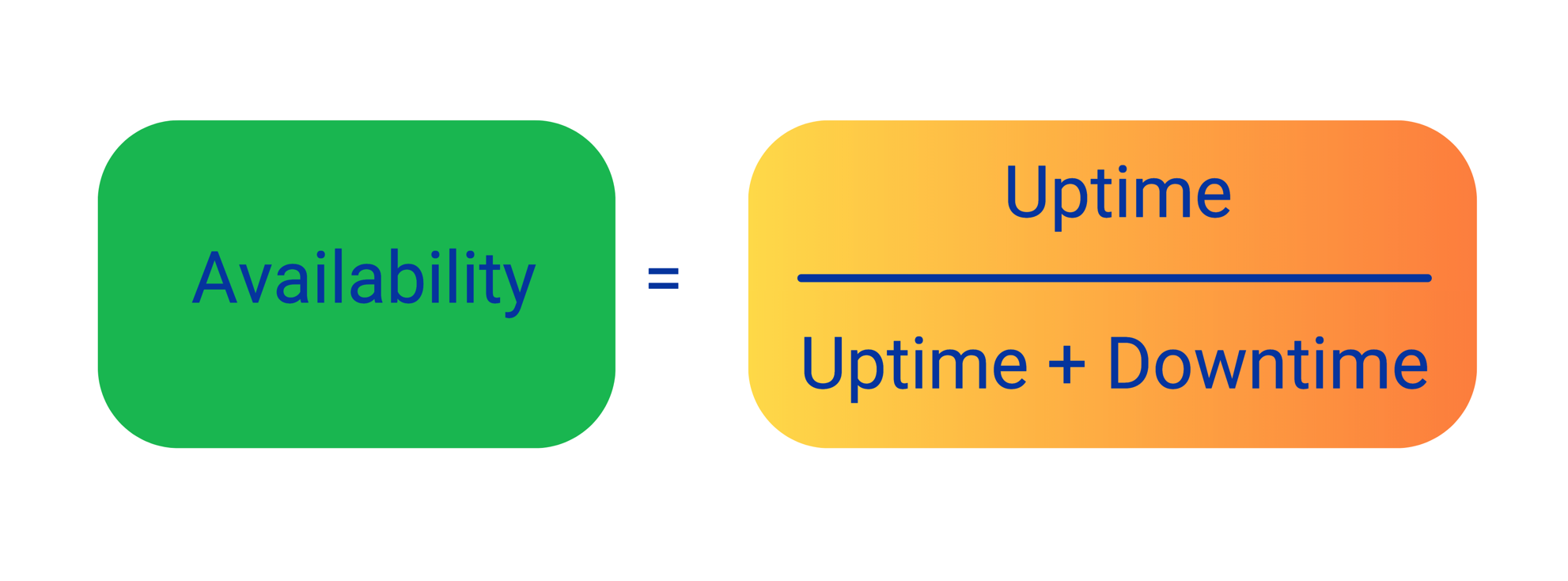
Availability is the proportion of time a system is in a functioning condition. It’s a key performance indicator in service level agreements (SLAs) and is crucial for ensuring continuous service delivery. Mathematically, availability is calculated as:
Availability = Uptime / (Uptime + Downtime)This can also be expressed using MTBF and MTTR:
Availability = MTBF / (MTBF + MTTR)Where:
- MTBF (Mean Time Between Failures) is the average time elapsed between two consecutive failures.
- MTTR (Mean Time to Repair) is the average time taken to repair a system and bring it back to operational status after a failure.
Mean Time Between Failures (MTBF)
MTBF is a reliability metric that predicts the time duration between inherent failures of a system during normal operation. It is calculated as:
MTBF = Total Operational Time / Number of FailuresExample:
Imagine a server that operates for 600 hours in a month and experiences 3 failures in that time:
- Total Operational Time = 600 hours
- Number of Failures = 3
Calculation: MTBF = 600 hours / 3 failures = 200 hours
This means, on average, the server runs for 200 hours before experiencing a failure.
Mean Time to Repair (MTTR)
MTTR measures the average time taken to repair a system and restore it to operational status after a failure. It includes diagnosis, repair, testing, and restoration times. MTTR is calculated as:
MTTR = Total Downtime / Number of FailuresExample:
Using the same server example, suppose the total downtime due to the 3 failures is 6 hours:
- Total Downtime = 6 hours
- Number of Failures = 3
Calculation: MTTR = 6 hours / 3 failures = 2 hours
This means, on average, it takes 2 hours to repair the server and bring it back online after a failure.
Calculating Availability
Now, let’s calculate the availability using the MTBF and MTTR from the examples above:
- MTBF = 200 hours
- MTTR = 2 hours
Availability = MTBF / (MTBF + MTTR)
Plugging in the values: Availability = 200 hours / (200 hours + 2 hours) = 200 / 202 ≈ 0.9901This means the server has an availability of approximately 99.01%.
Optimizing Availability
To improve availability, you can:
Increase MTBF: Enhance system reliability to reduce failure frequency.
- Example: Regular maintenance, using more reliable components, implementing fault-tolerant designs.
Reduce MTTR: Minimize the repair time through efficient maintenance procedures, better diagnostic tools, and trained personnel.
- Example: Implementing automated failure detection and repair mechanisms.
Practical Implications
In real-world scenarios, achieving high availability can have significant cost and resource implications. Here are a few tips for different environments:
- Data Centers and Servers: Use redundancy (like RAID for disks), high-quality hardware, and robust monitoring tools to quickly identify and resolve issues.
- Software Systems: Implement continuous integration and continuous deployment (CI/CD) practices, automated testing, and rolling updates to minimize downtime during deployments.
- Manufacturing: Regular preventive maintenance schedules and swift response teams can enhance machinery availability.
Conclusion
Understanding and calculating availability using MTBF and MTTR helps organizations maintain high levels of operational efficiency. By focusing on increasing MTBF and reducing MTTR, businesses can ensure better service uptime, leading to improved customer satisfaction and loyalty.
Focusing on these metrics allows for data-driven decisions in both the planning and operational phases, ensuring systems remain reliable and available when needed.
References for Further Reading:
- “Reliability, Maintainability and Risk: Practical Methods for Engineers” by David J. Smith
- “Availability Engineering and Management for Manufacturing Plant Performance” by Richard H. Richter